Detecting Cobalt Strike and Hancitor traffic in PCAP
This video shows how Cobalt Strike and Hancitor C2 traffic can be detected using CapLoader.
I bet you’re going:
😱 OMG he’s analyzing Windows malware on a Windows PC!!!
Relax, I know what I’m doing. I have also taken the precaution of analyzing the PCAP file in a Windows Sandbox, which just takes a couple of seconds to deploy and run.
The capture file I’m looking at is called “2021-05-13-Hancitor-traffic-with-Ficker-Stealer-and-Cobalt-Strike.pcap” and can be downloaded from here: https://malware-traffic-analysis.net/2021/05/13/index.html
CapLoader’s Services tab shows us that the connections to TCP 80 and 443 on
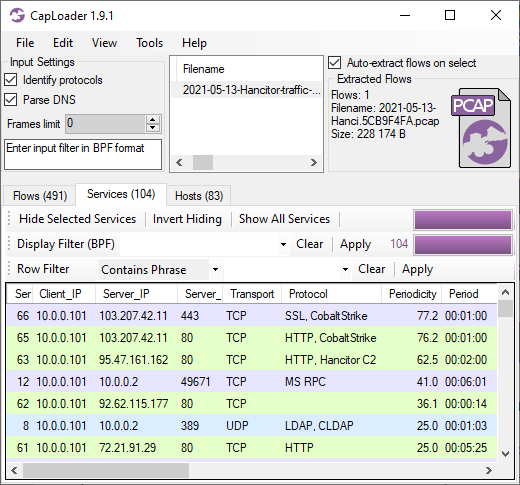
CapLoader uses machine learning to identify the application layer protocol based on the behavior of the traffic, not the port number. This means that there can be false positives, i.e. the protocol classification that CapLoader gives a flow or service might be wrong. It is more common, however, for CapLoader to yield false negatives, which means that it can't identify the protocol. The detection of Cobalt Strike inside of HTTP and SSL traffic was recently introduced in the latest 1.9 release of CapLoader. I expected this feature to detect Cobalt Strike traffic in HTTP, but I was delighted to see that CapLoader often detects even TLS encrypted Cobalt Strike beaconing with really good precision!
As shown in the video, the Cobalt Strike beacon config can easily be extracted from the network traffic using NetworkMiner and Didier Stevens’ 1768 K python script.
The output from Didier’s 7868.py tool looks something like this:
0x0002 port 80
0x0003 sleeptime 60000
0x0004 maxgetsize 1048576
0x0005 jitter 0
0x0007 publickey 30819f30[...]
0x0008 server,get-uri '103.207.42.11,/ca'
[...]
As you can see, it uses HTTP for transport with a “sleeptime” of 1 minute (60000 ms) and
Network Forensics Training
Are you interested in learning more about how to analyze network traffic from Cobalt Strike and other backdoors, malware and hacker tools? Then take a look at the live online network forensics classes I will be teaching in September and October!
Posted by Erik Hjelmvik on Monday, 31 May 2021 08:30:00 (UTC/GMT)
Tags: #Netresec #Cobalt Strike #CobaltStrike #periodicity #Protocol Identification #PIPI #CapLoader #1768.py #Windows Sandbox #PCAP #NSM #video #videotutorial

")